Linux Kernel Concept, Unix File system and Inode
(1) 유닉스 파일시스템과 Inode구조체
Before,
리눅스는 유닉스 계열의 시스템이다. 유닉스 계열의 시스템에서는 모든 것을 파일로 취급한다고 한다. (1%는 아닌 것도 있다고 한 것 같기도.. 이는 추후에 찾아보기로 한다.)
아무튼 리눅스에서는 일반파일(regular file) 뿐 아니라, 모니터나 키보드, 마우스, 네트워크 인터페이스 카드(NIC) 같은 디바이스 들도 몽땅 파일(device file)로 취급하여 관리한다. 따라서 파일의 관리는 굉장히 중요한 부분을 차지한다.
OS에서 파일을 관리하는 관리하기 위해 File system이라는 개념을 사용하는데 Disk를 예로 들자면 대충 이런식이다.
파일시스템은 보조기억장치를 관리하는 소프트웨어이다.
궁극적인 목표는 자원을 최대한 아껴서 사용하는 것이며 이를위해 정책(policies)을 가지고 내/외부 단편화를 관리한다.
이는 MMU나 MPU와 같은 메모리관리시스템(Memory Management System)도 마찬가지인데 둘 다 기억장치를 관리하는 소프트웨어이지만 File System은 사용자가 관리를 수월하게 하기위해 “Naming”이라는 특성을 사용하여 파일단위로 추상화하여 관리하도록 한다는게 다른점이라고 한다.
또한 파일시스템을 아래 그림처럼 같이 하나의 tree 구조로 관리한다.
Linux Directory Hierarchy
출처. Learning The Linux File System (http://freedompenguin.com/articles/how-to/learning-the-linux-file-system/)
유닉스 계열에서는 mount namespace1이 있어서 filesystem mount points의 sets별로 isolation할 수 있다. 다른 마운트 네임스페이스에 있는 프로세스들은 다른 파일시스템 계층 뷰를 가질 수 있다. 하드링크(hard link)/소프트링크(soft link) 기능이 가능한 이유인듯 하다. 리눅스에서는 프로세스별로 개별적인 마운트 뷰(view)를 가진다.
유닉스 파일시스템에서 모든 파일은 tree구조에 있기때문에 파일이나 폴더들은 각각 고유의 경로(path)로 표현된다. 예를들어 사용자 라이브러리 파일들은 /usr/lib/[파일]이라는 경로로 표현할 수 있다. 이때 경로를 이루는 항목인 “usr”, “lib”, “[파일명]” 각각을 디렉터리 엔트리(Directory Entry)라고하며 이를 묶어서 덴트리(Dentry)라고 한다.
이런식의 관리를 제공해주는 파일시스템의 디스크 할당 방식을 크게 두가지 방법으로 구분한다.
| 연속 할당방식 (sequential allocation) | 불연속 할당방식 (non-sequectial allocation) |
|---|---|
| 인접한 연속의 공간에 할당 | 인접하지 않은 공간에 할당 |
| 요구되는 크기 만큼의 인접한 공간이 존재해야함 | 해당 정보가 어디에 흩어져 있는지 위치정보를 따로 저장/관리해야함 |
| 불연속 할당방식보다 속도가 빠름 | 속도가 비교적 느림 |
| 파일의 크기가 변하면 문제가 됨 | 파일의 크기가 커져도 할당이 비교적 쉬움 |
일반적으로 불연속 할당방식이 사용되며 이는 다시 몇가지 방법이 존재한다.
블록 체인 기법
- 같은 파일의 정보를 저장하는 블록을 체인(포인터)로 연결
- 원하는 정보를 검색할 때(lseek()) 처음부터 읽어가야 함
인덱스 블록 기법
- 위치정보를 인덱스 블록이라는 별도의 공간에 블록을 두고 관리
- 파일마다 인덱스 블록을 가짐
- 검색 속도가 비교적 빠름(lseek())
- 인덱스 블록을 유실하면 해당 파일을 사용할 수 없음
- 파일의 수가 늘어날수록 인덱스 블록을 저장하는 공간이 많이 소비되게 됨
FAT(File Allocation Table) 기법
- 파일시스탬마다 위치정보를 FAT라는 자료구조에 저장
- FAT 정보를 유실하면 손해가 크기때문에 중복으로 관리
- 인덱스 블록 기법과 마찬가지로 처음부터 데이터를 읽어갈 필요가 없어 속도가 비교적 빠름(lseek())
하드디스크의 물리적 모습은 다음 그림과 같으며 이전에 정리한 것을 참고하도록 한다.
* Linux File System : http://jiming.tistory.com/120
(함께 참고. VFS : http://jiming.tistory.com/127)
(여기서 우선 알고넘어가야 할 점은 sector이다. sector는 데이터를 디스크에서 Read/Write하는 기본단위로 일반적으로는 512byte이다.)
리눅스의 디폴트 파일시스템인 ext4등 ext계열의 파일시스템에서는 인덱스 블록 기법과 유사한 Inode라는 구조를 채택해서 사용하고 있다.
Inode 개념은 두가지가 있다.
하나는 디스크에 기록되어 저장된 파일들 각각이 가지고있는, 파일 자신에 대한 정보를 담는 구조체이다. 또 하나는 시스템에서 사용을 위해 open() 시스템콜(system call)로 오픈한 파일에 대한 정보를 나타내는 객체로 메모리에서 관리되어지는 개념이다.
여기에서 말하려는 Inode구조는 첫번째 개념으로 파일이나 디렉터리에 대한 모든 정보를 가지는 자료구조로 해당 파일시스템에서 사용하는 Inode구조체이다. 즉 파일시스템과 관련되어 있으므로 /fs 디렉터리 내에 해당 파일시스템에 관련하여 정의되어 있다. 다음은 github에서 클로닝한 현재기준 커널버전 4.5 프로젝트2의 ext4 파일시스템에 정의된 inode 구조체이다. (* 참고로 메모리에서 관리하는 inode객체는 /include/linux/fs.h에 정의되어 있으며 추후에 정리한다.)
예. /fs/ext4/ext4.h
638 /*
639 * Structure of an on the disk
640 /
641 struct ext4_inode {
642 __le16 i_mode; / File mode /
643 __le16 i_uid; / Low 16 bits of Owner Uid /
644 __le32 i_size_lo; / Size in bytes /
645 __le32 i_atime; / Access time /
646 __le32 i_ctime; / Inode Change time /
647 __le32 i_mtime; / Modification time /
648 __le32 i_dtime; / Deletion Time /
649 __le16 i_gid; / Low 16 bits of Group Id /
650 __le16 i_links_count; / Links count /
651 __le32 i_blocks_lo; / Blocks count /
652 __le32 i_flags; / File flags /
…
664 __le32 i_block[EXT4_N_BLOCKS];/ Pointers to blocks /
665 __le32 i_generation; / File version (for NFS) /
666 __le32 i_file_acl_lo; / File ACL /
667 __le32 i_size_high;
668 __le32 i_obso_faddr; / Obsoleted fragment address /
…
691 __le16 i_extra_isize;
692 __le16 i_checksum_hi; / crc32c(uuid+inum+) BE /
693 __le32 i_ctime_extra; / extra Change time (nsec « 2 | epoch) /
694 __le32 i_mtime_extra; / extra Modification time(nsec « 2 | epoch) /
695 __le32 i_atime_extra; / extra Access time (nsec « 2 | epoch) /
696 __le32 i_crtime; / File Creation time */
…
700 };
주석만 봐도 이 구조체에 저장되는 내용이 어떤것인지 알 수 있다.
- i_blocks : 해당 파일이 가지고있는 데이터 블록의 갯수 저장
- i_mode : 해당 inode가 관리하는 파일의 속성 및 접근제어 정보 저장
- i_links_count : 해당 inode가 가리키는 파일 수(또는 링크 수)
- i_uid, i_gid : 파일을생성한 소유자의 id 및 group id
- i_atike, i_ctime, i_mtime : 파일의 접근시간, 생성시간, 수정시간
- ….
본디 파일시스템이 저장하는 정보에는 두가지가 있는데 바로 meta data와 user data이다.
- meta data : 파일의 속성정보, 데이터블록의 인덱스 정보 등
- user data : 사용자가 실제 저장하려는 데이터
위와같은 구조를 같는 Inode를 통해서 파일에 대한 모든 정보를 관리할 수 있다.
리눅스 기반의 운영체제에서 $ ls -l명령어를 실행하면 파일이나 디렉터리에 대해 다음과 같은 정보가 출력된다.
이러한 정보들이 해당 구조체의 정보를 사용해 출력되는 것이다.
$ umask, $ chmod, $ chown,$ lsattr, $ chattr 등의 명령어를 통해 파일/디렉터리에 관련한 정보를 설정 및 수정 할 수 있다.
Inode구조체에는 File mode를 의미하는 i_mode라는 16bit짜리 변수가 있다.
이 변수는 해당 inode가 관리하는 파일의 속성 및 접근제어 정보를 저장하는 변수로 다음과 같은 구조를 가진다.
상위 4bit은 파일의 유형(type)을 나타내며 ls -l의 결과인 아래그림에서 빨간색으로 표시한 부분이다.
유닉스 기반의 파일시스템에서는 모든 디바이스를 파일로 다룬다고 하였다. 이 4bit의 타입 필드가 해당 파일이 어떤 유형의 파일인지 나타내는 역할을 한다.
종류는 다음과 같다.
| 기호 | 종류 | 플래그 |
|---|---|---|
| - | 정규파일 | S_IFREG |
| d | 디렉터리 | S_IFDIR |
| c | 문자장치 | S_IFCHR |
| b | 블록장치 | S_IFBLK |
| l | 링크파일 | S_IFLNK |
| p | 파이프파일 | S_IFFIFO |
| s | 소켓파일 | S_IFSOCK |
그리고 하위 9개의 비트는 파일의 접근제어(사용자 / 그룹 / 기타사용자)를 의미하며 아래의 빨간부분을 의미한다.
그 다음 가운데 3비트는 각각 다음과 같으며, chmod 명령을 통해서 설정할 수 있다.
| 비트 | 종류 | 설정값 | 설명 |
|---|---|---|---|
| u bit | SETUID | 4000 | Set User ID, 파일이 수행될 때 수행시킨 태스크의 사용자의 권한이 아닌, 파일의 소유자 권한으로 동작할 수 있게 함 |
| g bit | SETGID | 2000 | Set Group ID, 파일이 수행될 때 수행시킨 태스크의 소유그룹 권한이 아닌, 파일의 소유그룹 권한으로 동작할 수 있게 함 |
| s bit | Sticky Bit | 1000 | 파일 및 디렉터리에 설정되는 접근권한을 나타내는 플래그 비트. 태스크가 메모리에서 쫒겨날 때(swap-out), swap 공간에 유지되도록 할 때(swap-in), 디렉터리에 대한 접근 제어에 사용 |
chmod 4755 파일명[or 디렉터리명]
chmod 2755 파일명[or 디렉터리명]
chmod 1755 파일명[or 디렉터리명]
(*755는 일반 퍼미션을 나타냄)
*파일의 속성에 대한 부분은 [이곳]을 참고하자.
그 다음 “Pointers to blocks”라는 주석이 달린 i_block이라는 변수를 살펴보자.
위에서 살펴본 i_mode 변수나 그 이외의 변수들이 파일의 메타데이터(meta data)를 저장한다면, i_block이 가리키는 블락의 주소라는 것은 바로 실제 저장된 데이터(user data)의 위치를 의미한다.
여기에서 보면 한 엔트리당 크기가 32비트인(포인터라서), 길이가 EXT4_N_BLOCKS인 배열변수이다. inode구조에서 i_block은 파일에 속한 디스크블록들의 주소를 저장하는 포인터배열이며 길이는 통상 15이다.
현재 최신버전의 리눅스커널 소스의 EXT4_N_BLOCKS은 다음과 같이 정의되어있다.
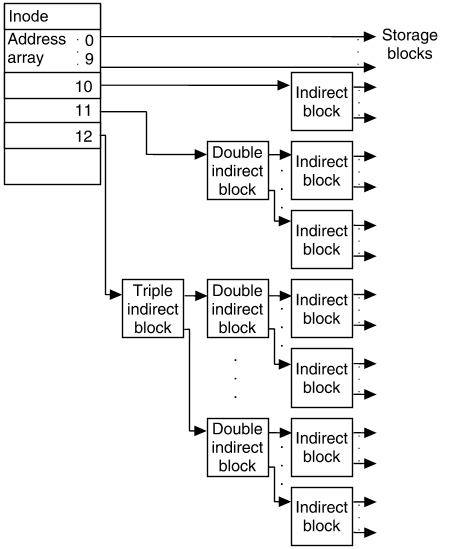
즉 여기에서도 총 15개의 엔트리로 구성되는데 12개는 direct block이라고 하며, 나머지 3개는 indirect block이다.
추측이지만, 소스 상에서 이를 적절히 활용해 쓰기위해 define을 저렇게 나누었을 것이다.
(normal direct block, indirect block, double indirect block, triple indirect block ?? ㅎㅎㅎㅎ)
아래는 inode 구조체에서 i_block 부분을 나타낸 모습이다.
우선 i_block 배열은 12개의 direct block과 3개의 indirect block으로 구성되어 총 15개의 엔트리를 갖는다고 하였다. direct block은 실제 파일의 내용을 담고있는 디스크의 데이터 블록을 가리키는 포인터변수이다. 그림에서 처럼 해당 파일에 속하는 디스크에 위치한 실제 데이터 저장장소를 가리킨다. 그런데 direct block은 12개 밖에 없다. 일반적으로 하나의 데이터 블록의 크기는 페이지프레임(page frame)의 크기와 동일하므로 일반적으로 4KB가 되는데 이대로라면 4KB짜리 데이터 블록 12개만큼을 한 파일에서 저장공간으로 사용할 수 있다는 이야기가 된다. 계산해보자. 4KB * 12개 = 48, 즉 0-11까지의 총 12개의 직접블록으로 가질 수 있는 한 파일의 최대 크기는 고작 48KB이다.
이는 절대 말이되지 않는다. 이와 상반되게 이번엔 indirect block(간접블록)이 어떻게 동작하는지 알아보자.
우선 간접블럭이라는 말은 디스크 상에 해당되는 위치를 직접적으로 가리키는 것이아니라 인덱스를 저장하는 인덱스블록을 중간에 더 두고 이를 거쳐서 가리키게 하는 것이다. indirect block은 그림에서 처럼 3개로 나뉜다. (그림에서는 single indirect block만 디스크에 표시)
single indirect block : 단일 간접블록, 하나의 인덱스 블록을 가짐
double indirect block : 이중 간접블록, 2단계의 인덱스 블록을 가짐
triple indirect block : 삼중 간접블록, 3단계의 인덱스 블록을 가짐
single indirect block은 하나의 인덱스 블록을 갖는다고 하였다. 하나의 데이터 블록을 인덱스 블록으로 만든 후 더 많은 데이터 블록을 가리키게 하는 것이다. 이렇게 하면 고작 하나의 데이터 블록의 크기로 훨씬 더 많은 데이터 블록을 가리킬 수 있게 된다.
이제 single indirect block으로 지원가능한 파일의 크기를 알아보자. 한개의 블록이 4KB(즉 4096byte)라고 가정3한다고 했고, 주소를 가리키는 포인터는 4byte이다. 계산을 해보면 한 블록으로 (4096byte / 4byte = ) 1024개의 포인터를 표현할 수 있고 이 말은 즉, 한 블록이 가리킬 수 있는 주소공간은 1024개가 되는 것을 의미한다. 위에서 한 블록의 최소 크기가 4KB이라고 가정하였으니 single indirect block으로 표현할 수 있는 한 파일의 최대 크기는 4KB(데이터블록 한개) * 1024개(의 포인터) = 4096KB, 즉 4MB가 된다.
그렇다면 double indirect block은 어떨까? 말그대로 인덱스 블록을 이중으로 가진다.
계산해보자. 1024개 * 1024개 * 4KB(한 블록의 크기) = 4GB, 즉 double indirect block로 가질 수 있는 최대 파일의 크기는 4GB이다.
triple indirect block도 마찬가지이다. 인덱스 블록을 3중으로 가지므로 계산은 1024 * 1024 * 1024 * 4KB = 4TB 이렇게 된다.
즉, 여기서의 최대 파일의 크기는 4TB이다.
최종적으로 inode구조에서 지원할 수 있는 최대 파일의 사이즈는 direct block + single indirect block + double indirect block + triple indirect block이므로 48KB + 4MB + 4GB + 4TB가 된다.
하지만 32bit환경에서 리눅스가 지원하는 실제 파일 사이즈는 4GB(or 2GB)인데, 이는 node가 4TB정도의 파일을 지원할 수 있다고 하더라도, 리눅스 커널 내부의 파일 관련 함수들이 사용하는 변수나 인자들이 32bit로 구현되어 있기때문이다. (예. f_pos, 2^32 = 4GB…… 가 표현할 수 있는 최대 file offset이 됨)
전체적인 그림은 이걸 참고하자. (출처. http://uw714doc.sco.com/en/FS_admin/graphics/s5chain.gif)
이렇게 파일마다 가지고 있는 inode구조체를 파일시스템에서는 어떻게 각각의 파일과 연결하여 저장하는 것일까?
이를 위해서 “디렉터리 엔트리(Directory Entry)”라고하는 테이블을 사용하며 구조는 아래와 같다.
디렉터리 엔트리는 간단한 정보만 유지하고 실제 데이터 블록 인덱스 등의 세부적인 정보는 inode 번호를 통해 inode 자료구조에 접근해 사용한다.
디바이스 파일들은 /dev 디렉터리 밑에 위치하게 된다. /dev는 각종 디바이스의 디바이스 드라이버들이 저장되어 있는 디렉터리이다.
- IDE 디스크: /dev/hd
- SCSI 디스크: /dev/sd
- CDROM: /dev/scd
- COM 시리얼 포트: /dev/ttyS
- 콘솔장치: /dev/console
- …: /dev/…
같은 종류의 디바이스에 대하여 디바이스 드리이버는 하나4이므로 같은 종류의 장치에 대해서는 a, b, … 식으로 네이밍이 된다.
또 디스크 내의 파티션은 1, 2, … 처럼 숫자로 네이밍이 된다. 아래의 그림을 참고하자.
디스크마다 최대 64개의 파티션을 만들 수 있으며 파일시스템은 각 파티션마다 설치된다. $ mkfs 명령어를 사용하여 파티션에 파일시스템을 생성할 수 있다.
EXT 계열의 파일시스템은 크게 부트스트랩 코드가 들어있는 Boot Block과 N개의 Block Group이라는 것으로 구성되어있다.
Boot Block에는 파티션의 부트섹터를 위해서 예약되어져 있으며 LILO나 GRUB이 들어간다. Block Group이라는 것은 파일을 저장할 때 인접한 부분에 데이터를 기록함으로써 Disk의 효율(seektime)을 높이고자 하는 개념이다.
Block Group은 다음과 같이 구성되어있다.
Super Block
- 파일 시스템의 전체적인 정보를 저장
- 파일 시스템의 크기, 마운트 정보, 데이터 블럭의 갯수, inode 갯수, 블럭그룹 번호, 블록의 크기(1KB, 2KB, 4KB), 그룹당 블룩 수, 슈퍼블록의 수정여부 정보
Group Descriptor (GDT)
- 해당 파일 시스템 내의 모든 Block Group들의 정보를 저장
- Block Bitmap의 블럭 번호, Inode Bitmap의 블럭 번호, 첫번째 Inode Table Block의 블럭 번호, 그룹안에 있는 빈 블럭 갯수, 그룹안에 있는 inode의 갯수, 그룹안에있는 빈 디렉토리 갯수
- 크기가 일정하지 않아 Block Bitmap의 위치에 영향을 미치므로 그 위치 정보도 저장
Block Bitmap
- 데이터 블록 내에서 빈 공간을 관리하기 위해 사용
- Block 사용 현황을 bit로 표현 (Super Block, Group Descriptor Block, inode table block 등등)
- 한 블럭그룹 내의 각각의 블럭은 Block Bitmap의 각각의 bit에 대응
- 사용중인 block은 Block Bitmap의 해당되는 인덱스의 값이 1로, 사용중이지 않으면 0으로 표현
Inode Bitmap
- inode table 내에서 빈 공간을 관리하기 위해 사용
- Inode 사용 현황을 bit로 표현
- 한 블럭그룹내의 각각의 inode는 Inode Bitmap의 각각의 bit에 대응
- 사용중인 inode는 Inode Bitmap의 해당되는 인덱스의 값이 1로, 사용중이지 않으면 0으로 표현
Inode Table
- inode들을 관리
- 파일 시스템 구축 시 계산된 값으로 결정. 고정된 값을 가짐
- 인접하는 연속된 블럭으로 구성. 각 블럭은 미리 정의된 inode 갯수를 포함
- Inode Table의 첫 번째 블럭번호를 Group Descriptor에 저장
- 모든 inode 구조체의 크기는 128byte
- 한 블록 내에 X개의 inode가 존재
ex. default는 4096byte.
1024byte의 inode table block은 8개의 inode를 가질 수 있음
2048byte의 inode table block은 16개의 inode를 가질 수 있음
4096byte의 inode table block은 32개의 inode를 가질 수 있음
디스크가 남더라도 최대 숫자가 넘으면 파일 생성을 할 수 없음.
Data Blocks
- 파일에서 데이터를 저장하는 블럭
- inode에 포함되어 있으며, inode는 몇개의 데이터 블럭을 포함
참고. 리눅스에서는 sector가 512byte이다. 한번에 데이터를 read/write하는 블록 단위가 4KB(4096byte)일때, 8개의 sector가 대응되어야 한다.
슈퍼블록과 GDT는 사실상 파티션에 한 곳에만 저장되어도 되는 내용이지만, 데이터가 손상된다면 문제가 심각하게 될 수 있기 때문에 Block Group 마다 정보를 복사해 가지고 있는다.
그리고 각 Block Group 내에서는 어디까지 데이터가 기록되어 있는지에 대한 정보를 가지고 있어야 하는데 이를 이를 위해 Block bitmap과 Inode bitmap이 사용된다. Block bitmap와 Inode bitmap는 각각 자신의 영역의 비트로 해당 Block Group내에서의 블록 및 inode의 사용상태를 나타낸다.
(이 예제는 “리눅스커널 내부구조”라는 책에 나와있다.)
root 밑에 File1.c와 mydir을 생성했다고 하므로써 disk block이 24까지 사용되었고, inode는 12까지 사용되었다. (참고로 root의 inode number는 2로 이미 설정되어 있으며, 일반 파일 생성 시 처음 할당되는 inode번호가 11이 되는 것도 이미 설정되어 있다.)
이를 bitmap으로 표현하면 아래 그림과 같다.
사실 Block bitmap과 Inode bitmap은 한 블록내에 존재하며, 만약 블록이 4096byte * 8개의 블록을 표시해야 한다.
EXT4는 기존의 EXT 시스템과는 달리 48bit의 주소체계를 사용하며 Extent 및 다른 변경된 기능을 사용한다. 이 부분에 대해서는 나중에 추후에 정리하도록 하겠다. 참고. http://behonestar.tistory.com/9
EXT2, 3, 4의 간단한 내용은 이전 포스팅에 있다. Linux File System: http://jiming.tistory.com/120
이것으로 리눅스의 파일시스템의 기본개념을 디폴트 파일시스템인 ext4의 inode구조와 더불어 알아보았다. 다음에는 VFS과 더불어 알아보도록 하겠다.
-
리눅스 Namespaces로 IPC, Network, Mount, PID ,User, UTS 같은 Namespaces가 있다. 특히 PID Namespace를 사용하면 같은 isolation구역의 프로세스들은 같은 PID로 관리되어지며 suspending/resuming 등의 기능을 사용할 수 있다. 프로세스가 생성될 때 부모프로세스가 복사되어 생성되면서 가지게되는 부모프로세스의 PID가 새로 할당받는 자신의 PID와는 별도로, 해당 isolation 영역에서의 PID로 사용되는 듯 하다. 실제로 프로세스 관련 폴더인 /proc폴더에서 해당 프로세스의 폴더로 들어가면 namespaces들에 대한 내용을 비롯한 프로세스 별로 관리되는 정보들이 존재함을 확인할 수 있다. 상세한 내용은 man pages를 참고하자. Namespaces는 Docker등과 같은 클라우드환경에서 cgroups과 함께 활용되고 있다. ↩
-
리눅스 토바르발즈의 리눅스커널 git (https://github.com/torvalds/linux/) ↩
-
여담으로 데이터블록의 최소 단위가 4KB라고 가정하였으므로, 최소 파일의 크기도 4KB가 된다. 파일에 아무것도 기록하지 않아도 생성자체만으로도 4KB를 확보하게 된다는 말이다. ↩
-
추후 설명할 예정인 장치관리자의 메이저/마이너 넘버와 연관하여 생각해보자. ↩